The (Normally and Independently Identically Distributed) assumption for the error component means:
The above assumptions can be further elaborated as:
1. Zero mean assumption
The error is the deviation of the estimation to the true value. Thus ideally, the error should be minimized to give the most accurate prediction, i.e., the mean of the error should be as close to 0 as possible.
This is written mathematically as . As a result, we may obtain the following expectation for :
2. Normally distributed assumption
The model should be as close as possible to each data point. This assumptions prevents overfit or underfit problem.
The error should be small. And if it’s large, the frequency should be less than those with smaller deviation.
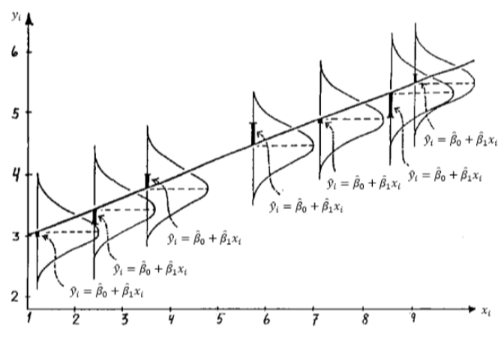
Illustration of normality assumption for error terms
3. Constant variance assumption (homoscedasticity)
Variation of (and hence, variation of ) is the same across conditions represented by . In simpler terms, regardless of the value of the predictor , the spread (variance) of the error term should remain constant.
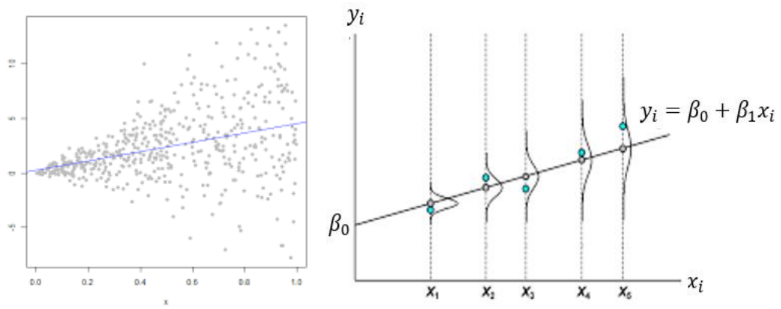
Example of model that violates the constant variance assumption
4. Independency assumption
An error is not related with others errors; knowing the error for one observation should give no information about the error of another.